Uma abordagem para deduzir como o mundo virou de cabeça para baixo. Neste artigo apresentarei à você os principais conceitos e componentes do padrão arquitetural conhecido como event sourcing.
https://medium.com/@diego_moura/event-sourcing-big-picture-86cc36a2c851
Breve história…
O termo software foi mencionado pela primeira vez na década de 50, em um artigo escrito pelo estatístico John Wilder Tukey. Turkey também cunhou o termo bit, que representa o digito binário.
Um software é um conjunto de instruções ou operações que são interpretadas por um computador, afim de realizar alguma tarefa específica.
1940 — Vamos trabalhar com a definição cronológica de que o primeiro software criado surgiu na Inglaterra, na década de 40, e foi escrito pelo matemático húngaro John Von Neumann.
1950 — Na década de 50 surgiu o conceito de sistemas operacionais, introduzido pela GM Laboratories na criação do computador da segunda geração o IBM 701.
1965 — A IBM lança um sistema operacional avançado com compartilhamento de recursos e suporte à discos, o OS/360.
1969 — Ken Thompson e Dennis Ritchie, criaram a primeira versão do UNIX. Os também criadores das linguagens de programação B e C.
1972 — Marc Rochkind criou o primeiro sistema de controle de versão de software enquanto trabalhava na Bell Labs. Marc o batizou como Source Code Control System (SCCS).
Para iniciar nosso estudo de caso, nossa timeline para por aqui. Percebam que os primeiros softwares foram escritos na década de 40, e até o ano de 1972 não havia sistemas de controle de versão de software. Ou pelo menos, não encontrei registros oficiais a respeito. A pergunta é, como era a vida desses pobres desenvolvedores antes do sistema de controle de versão!!? 😱😱😱Certamente triste e vazia…😭
Imagine termos que lidar com conciliações de arquivos, com conflitos de código fonte, gerenciar atualizações de código, gerenciar histórico de mudanças e principalmente termos condições de reverter o estado atual de uma aplicação para um estado anterior, em consequência de um bug que tivesse sido introduzido em uma versão mais recente. Imagine ter que lidar com tudo isso, sem o suporte de ferramentas como Git, CSV, Mercurial, SVN, etc… Infernal né??!

A principal característica de ferramentas de controle de versão, é a capacidade de armazenar e gerenciar com granularidade o histórico de mudanças de tudo que for implementado a partir do codebase.
Com ferramentas como GIT você pode facilmente rastrear o histórico de mudanças, visualizar o que foi feito, quem a fez, quando a fez, como a fez, e porque esta mudança foi implementada. Além desses recursos, você pode fazer consultas temporais no repositório base para verificar o estado da sua aplicação em determinado momento no passado, resolver conflitos com facilidade, e etc. Coisa linda né?
Agora… Reflita sobre os seus dados! Seu banco de dados tem a capacidade de gerenciar o histórico de mudanças dos seus dados? 🤔
Bom… A menos que você utilize um sistema de banco de banco de dados como EventStore, Datomic ou Crux, creio que a resposta seja não!
Mas somos engenheiros não é?? Damos jeito para tudo… Por muitas vezes para resolver esse problema, usamos alguns artifícios para nos ajudar a entender o estado atual do dado, e pra isso criamos atributos como updated_at, created_at, updated_by_user, deactivated_at, etc… Além disso, definimos estratégias de backups de dados, baseadas em diversas políticas, snapshots, etc… E mesmo assim quase nunca conseguimos concluir como os dados correntes chegaram no estado atual que estão na aplicação. E é a partir daí que introduziremos Event Sourcing.
Podemos consultar o estado de uma aplicação para descobrir o estado atual do mundo, e isso responde à muitas perguntas. No entanto, há momentos em que não queremos apenas ver onde estamos, mas também queremos saber como chegamos lá. — Martin Fowler
Event Sourcing
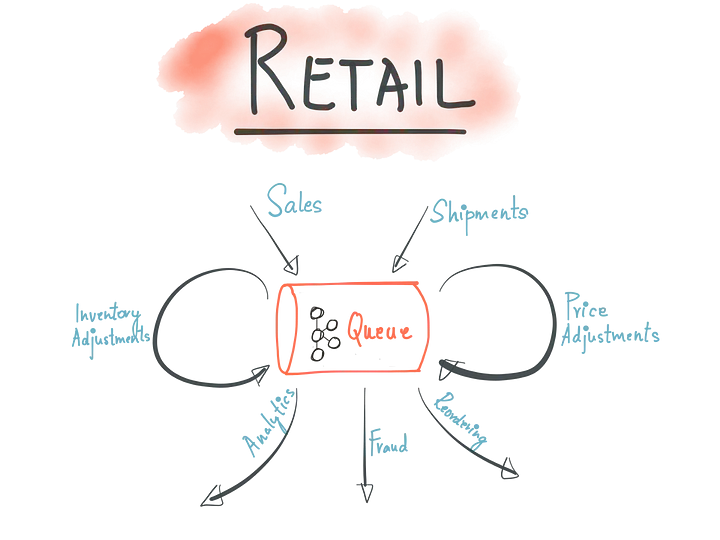
Event sourcing é um padrão arquitetural que tem como proposta central, garantir que todas as mudanças de estado da aplicação, gere um objeto de evento imutável, que será armazenado em um repositório de eventos, na mesma sequência a qual foi inserido. E que esses dados poderão ser consultados não apenas para dizer qual o estado atual da aplicação (como acontece em sistemas que utilizam o padrão de gerenciamento de dados convencional — Sob a ótica de bancos de dados tradicionais), mas também para deduzir como o estado atual foi concebido, através do histórico de eventos.
Componentes arquiteturais
O fato é que você pode trabalhar a implementação de event sourcing conforme sua necessidade. Pode haver mais ou menos componentes, as abstrações são diversas, não há uma especificação ao entorno dos componentes arquiteturais. No entanto, aqui mostro alguns componentes que comumente você irá percebe-los em arquiteturas baseadas em event sourcing.
Events
São objetos simples, imutáveis, que remetem à uma mudança de estado da aplicação. São ocorrências de negócios, que devem se autodescreverem.
Event Store
Repositório de eventos. Pode ser qualquer estrutura não volátil de armazenamento. Um banco de dados relacional, não relacional, um sistema de arquivos, etc.
Event Stream
Um fluxo (pense numa lista) de eventos gerado a partir de 1 ou N producers, que pode ser consumida a qualquer momento por 1 ou N consumers.
Aggregates
Basicamente representa o estado atual da aplicação.
Consumers or EventReaders
São responsáveis por ler os eventos e atualizar o estado atual dos dados nos aggregates correspondentes.
Producers or EventWriters
São responsáveis por gerar os eventos e inseri-los no event stream.
Algumas vantagens…
- Essa arquitetura traz consigo um grande potencial de escalabilidade horizontal, considerando que a concorrência não será um problema em questão, já que os objetos de eventos são inseridos no repositório de eventos sequencialmente, somente através de operações de inclusão.
- Você poderá desconsiderar completamente o estado atual dos dados na aplicação, e reproduzi-los inteiramente com base no histórico de eventos, quantas vezes for necessário com custo/esforço muito baixo.
- Você será capaz de determinar o estado dos dados da aplicação, a qualquer momento que desejar, apenas por reprocessar os objetos de eventos com base em consultas temporais no repositório de eventos, a partir de um estado vazio ou em branco.
- Se em algum momento um bug for introduzido em produção, você poderá realizar uma operação de “checkout ”no nível do dado. O comportamento seria semelhante ao que temos quando executamos o comando git checkout ‘master@2020–05–25 11:30:00’, no caso, você faria uma consulta temporal no event store, com base na data específica em que o bug foi implantado, e reverteria os eventos posteriores à data de implantação do bug, reprocessando novos eventos baseados na nova correção. E Voila!
- Como os objetos de eventos são persistidos somente através de operações de insert, naturalmente você passa a ter um histórico de logs fiel, que poderá lhe servir como fonte de verdade para auditoria de dados, monitoramento das ações executadas em uma base de dados secundária, testing & debugging, etc.
Nem tudo são flores… Algumas desvantagens:
- O event store é única fonte de verdade para as aplicações ou fluxos baseados em event sourcing. E como sabemos os dados são imutáveis e não há APIs para atualizações dos objetos de eventos no event store. Então se você precisar atualizar alguma informação, você terá que inserir um evento de compensação no repositório de eventos, e reprocessa-lo se necessário.
- Reflita sobre consistência… Naturalmente quando lidamos com arquiteturas ou padrões de comunicação baseados em eventos (EDA, Event Streaming, Pub/Sub, Event Sourcing), precisamos estar preparados para lidar com consistência eventual. No caso de event sourcing, não é diferente. Sua aplicação deve estar preparada para lidar com inconsistências ocasionadas pelo comportamento de consistência eventual que se tem ao comunicar aplicações sob a ótica de eventos.
- Não é uma regra mas… Em muitos casos, quando você utilizar Event Sourcing, naturalmente você inclinará sua arquitetura à utilizar o padrão arquitetural CQRS (Command Query Responsability Segragation) afim de separar as responsabilidades de escrita e leitura em componentes de baixo nível (ou alto nível, dependerá da sua necessidade), comunicando com bases ótimas para cada operação.
- Não há muitas ferramentas de suporte para auxiliar a implantação do padrão conforme sua especificação. Temos à nossa disposição algumas plataformas de Event Streams, que geralmente tem um curva de aprendizado longa. E implementar event sourcing sem o suporte de uma plataforma de stream, pode ser uma tarefa dolorosa.
Casos de uso
Quando você deveria cogitar utilizar Event Sourcing em suas aplicações?
- Quando houver a necessidade de armazenar dados imutáveis e que devem ser utilizados como única fonte de verdade para a aplicação.
- Quando for um requisito de negócio a capacidade de se trabalhar com N timelines no nível do dado para realização de qualquer operação de avaliação, monitoramento ou processamento posterior.
- Quando o sistema não admite ocorrências de conflito de atualizações de dados no contexto de execução da aplicação.
- Quando se faz necessário ter um histórico de log ativo e fiel, que pode ser utilizado para auditoria de dados.
- Quando suas aplicações já estão submetidas ao universo de comunicação sob eventos, e não houver esforços adicionais para a implementação. (Cuidado para não tornar essa implementação um overkill)
- Quando se há a necessidade de escalar suas aplicações horizontalmente e a consistência forte não for um requisito crucial para sua aplicação.
Quando NÃO devo usar Event Sourcing
- Não perca tempo implementando esse padrão se seu sistema tem pouca ou nenhuma lógica de negócios, ou seus domínios de negócio são simples ou pequenos demais.
- Se consistência forte for um requisito crucial, definitivamente não opte por event sourcing ou qualquer outra abordagem baseada em eventos que você não consiga facilmente atualizar os dados em tempo real, disparando uma solicitação síncrona para atualizar os dados das bases de leitura de forma automática.
- Sistemas onde o histórico de mudanças de estado não é necessário ou é indiferente para o negócio.
- Sistema onde as ocorrências de atualizações de dados conflitantes sejam muito baixas. Neste caso, sistemas em que terá um volume de operações de ESCRITA maior que de ATUALIZAÇÕES.
Conclusão
Assim como outros padrões arquiteturais, Event Sourcing está aí para nos ajudar a resolver alguns problemas específicos. Existem diversas plataformas de Event Streaming disponíveis no mercado que nos possibilitam a implementar esse padrão com mais fluidez e menos atrito. No entanto, esse é um pattner agnóstico, e é livre de qualquer recurso tecnológico ou linguagem de programação.
Bom!! É isso ai! Espero que tenham gostado e que eu possa ter contribuído de alguma forma!
#happycode